Newsletter
Suscríbete a nuestro Newsletter y entérate de las últimas novedades.
https://centrocompetencia.com/wp-content/themes/Ceco


El pasado miércoles 11 de junio, el equipo del proyecto “Computational Antitrust” de la Universidad de Stanford, en conjunto con OCDE Competition Law and Policy, realizaron el evento “The Computational Antitrust Event”. En él, Thibault Schrepel (Profesor Asociado en Amsterdam Lay & Technology Institute) y Teodora Groza (editora en jefe de Computational Antitrust) presentaron el reporte “Computational Antitrust Within Agencies: 3rd Annual Report” (“Reporte Stanford”). Además, el evento contó con los comentarios de Frederic Jenny (Director del Comité de Competencia de la OCDE) y William Kovacic (ex Comisionado de la FTC).
El objetivo del Reporte Stanford es compilar los avances que han tenido las agencias de libre competencia durante el último año en términos de integración e implementación de herramientas computacionales en sus operaciones (ver nota CeCo: “Agencias de competencia y el uso de herramientas computacionales”).
El propósito de esta nota es realizar un “barrido” de los avances del computational antitrust discutidos en el evento. Primero se comentarán los avances destacados en el Reporte Stanford, y luego se revisarán las innovaciones y conclusiones de algunos papers de investigación publicados entre fines de 2023 y comienzos de 2024 (que también fueron comentados en el evento).
El Reporte Stanford (cuya versión más reciente es la tercera) ofrece una visión de carácter global, abarcando los avances de 15 agencias de libre competencia en diversas regiones del mundo. Así, se incluyeron los avances de países americanos (Brasil, Canadá y Colombia); europeos (Bulgaria, Cataluña, República Checa, Dinamarca, Finlandia, Francia, Países Bajos, Polonia, Eslovaquia y España); y asiáticos (Arabia Saudí y Singapur). La inclusión de Arabia Saudí es particularmente interesante, ya que marca la primera aparición de un país del Medio Oriente en este tipo de reportes.
En el núcleo del computational antitrust se encuentra el desarrollo de herramientas de inteligencia artificial (“IA”), aprendizaje automático (“ML”, por sus siglas en inglés) y modelos de lenguaje grande (“LLM”).
En este sentido, las actualizaciones más frecuentadas en el Reporte Stanford dan cuenta de, por un lado, la digitalización de documentos y la optimización de procesos (al respecto, Kovacic destacó el proyecto de jurisprudencia de CeCo) y; por otro, la implementación de estas tecnologías en la aplicación de la ley de competencia (por ejemplo, en la detección de bid-rigging). El reporte señala que la adopción de estas tecnologías vanguardistas por parte de las agencias implicaría que estas se pongan al día con el mercado y sus actores, reduciendo así la brecha tecnológica (para complementar, ver nota CeCo: “Hacia la reforma tecnológica del antitrust en EE.UU.”).
A continuación, veremos los avances comentados por las agencias de Brasil, Colombia, España.
La agencia de competencia de Brasil, CADE, se encuentra hace años desarrollando un proyecto de análisis e investigación de datos llamado “Cerebro”, que capitaliza la robusta cultura brasileña de acceso a datos públicos. El Reporte Stanford hace presente que esta cultura se sustenta en diversos esfuerzos institucionales para aumentar la transparencia, en este caso, sobre licitaciones públicas y sus resultados. En este sentido, Cerebro aprovecha esos datos para reconocer comportamientos colusivos.
Para esto, Cerebro trabaja con dos categorías de información: (i) información para identificar a las partes que participan en licitaciones -es decir, localización, direcciones IP, etc.- y; (ii) información de las licitaciones enfocada en el comportamiento de las empresas. Esta última categoría contempla firmas que participan en conjunto en licitaciones, firmas que ganan licitaciones pero que no cumplen sus contratos, firmas que nunca ganan y firmas que siempre ganan en ciertas zonas geográficas. Estas variables permitirían identificar patrones que levantarían sospechas sobre posibles conductas coordinadas (bid-rigging).
Las herramientas tecnológicas con las que contaría Cerebro para realizar este procesamiento se dividen en los siguientes grupos: (i) técnicas de análisis de indicadores económicos y estadísticos; y (ii) uso de ML y software open source (código abierto). Además, Cerebro estaría planeando agregar herramientas de procesamiento natural de lenguaje (“NLP”, por sus siglas en inglés) y LLM para procesamiento de contrataciones públicas, particularmente en la búsqueda de documentos u otras formas de evidencia.
Ahora bien, el CADE identifica una serie de desafíos con respecto a la implementación de estas tecnologías. Por un lado, los productos de Cerebro deben ser interpretados por jueces que podrían tener un bajo o nulo entendimiento de la tecnología usada, o bien de la teoría económica y estadística detrás del funcionamiento. Al respecto, el equipo de Cerebro tendría el desafío de comunicar con claridad los procedimientos, resultados y conclusiones de forma que sean interpretados correctamente. Por último, la agencia brasileña también identificó un desafío con respecto a la obtención y mantención de mano de obra calificada que permita la ejecución de este tipo de proyectos. Este desafío adquiere vital importancia si consideramos el contexto latinoamericano, donde el capital humano es relativamente más escaso.
Actualmente, la institución encargada de velar por la libre competencia en Colombia, la Superintendencia de Industria y Comercio, ha desplegado una serie de herramientas tecnológicas con distintos objetivos, a saber: (i) mejorar las capacidades para detectar comportamientos anticompetitivos; (ii) optimizar el procesamiento de datos y; (iii) optimizar el uso de capital humano.
Las 5 herramientas desplegadas por la SIC especificadas en el Reporte Stanford son:
Al respecto, el Reporte Stanford no es específico en cuanto a las tecnologías específicas que constituyen cada herramienta.
La Comisión Nacional de Mercados Competitivos de España (“CNMC”), tiene una Unidad de Inteligencia Económica (“UIE”) que emplea IA para detectar formas nuevas y tradicionales de conductas anticompetitivas, mejorando también la detección ex officio (investigaciones iniciadas por la CNMC).
Esta unidad cuenta con una extensiva base de datos, que contempla información de la Plataforma de Contratación del Sector Público (“PSPP”) y del Ministerio de Hacienda español, y contiene más de 3,5 millones de contratos. Asimismo, contiene data estructurada (bases de datos) y no estructurada (documentos relacionados). Esta base de datos actualmente ayuda a la detección de posibles casos de bid-rigging.
Para esto, la UIE desarrolló la herramienta Bid Riging Algorithm for Vigilance in Antitrust (“BRAVA”). Esta, es basada en ML y es capaz de clasificar las ofertas en licitaciones de acuerdo a su probabilidad de ser colusivas o competitivas. De acuerdo con el Reporte Stanford, esta herramienta tendría un mínimo de 90% de probabilidad de ser exitosa.
Por último, otra aplicación de IA que ha desarrollado la UIE es el uso de herramientas open source intelligence («OSINT») y human intelligence (“HUMINT”). Esto, con el fin de lograr identificar organizaciones y personas de interés, sus relaciones y el grado de control que estas tienen cuando se trata de empresas que están bajo el escrutinio de las instituciones.
Como se mencionó anteriormente, adicional al comentario del Reporte Stanford, se cubrieron artículos de investigación publicados por el centro con el objetivo de colocar sobre la mesa los últimos avances académicos en materia de computational antitrust.
El artículo “Opening the Black Box: Uncovering the European Commission’s Cartel Fining Formula Through Computational Analysis”, de los investigadores Bruno Van den Bosch y Friso Boesten (Universidad Católica de Leuven), explora la predictibilidad de las multas impuestas por la Comisión Europea (“CE”) relacionadas a colusiones. Los investigadores, utilizan una metodología de ML, para comprobar si existe un “sesgo proteccionista” respecto de multas hacia empresas europeas en contraposición a las multas hacia empresas “extranjeras” a la Unión Europea. Con esta tecnología, los autores logran encontrar una “fórmula” para el cálculo de las multas.
Figura 1: Predicción de multas (eje horizontal) versus multas reales (eje vertical)
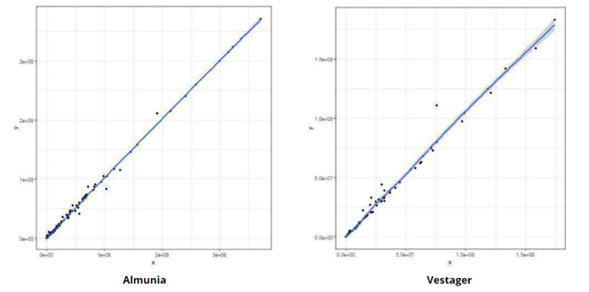
Fuente: Extraído de Van den Bosch y Boesten (2023)
Los puntos en el gráfico muestran qué tan cerca se encuentran las predicciones del modelo con respecto a las multas reales, en la medida que un ajuste cercano de los puntos a la línea diagonal indicaría una alta precisión del modelo en predecir las multas. Al respecto, el modelo desarrollado por los investigadores efectivamente tiene una capacidad de predictibilidad notoria respecto de las multas impuestas por la CE, específicamente para los periodos de Vestager (2014-actualidad) y Almunia (2010-2014) como comisionados.
Esta investigación proporciona una inspección del proceso de establecimiento de multas, y establece un precedente metodológico para futuras investigaciones. De la misma forma, es posible delinear la importancia de la transparencia y la consistencia en la aplicación de la ley de competencia, en la medida que un entorno predictible y justo es deseable para la proliferación de un sistema de libre competencia (para profundizar en esta investigación, ver nota CeCo: “La caja negra de las multas: Análisis computacional de su aplicación por la Comisión Europea”)
Otro artículo comentado fue “Using Natural Language Processing to Delineate Digital Markets” por los investigadores Klaus Gugler, Florian Szucs y Ulrich Wohak, de la Universidad de Economía y Negocios de Viena. Los investigadores desarrollan un modelo de NLP para reconocer competidores en mercados digitales. Para esto, recopilan las descripciones auto-reportadas de las firmas. En síntesis, el modelo computacional interpreta el texto y evalúa niveles de semejanza para determinar si corresponden a la descripción de la empresa “base”.
Para determinar la efectividad de este algoritmo, los autores realizaron el ejercicio con casos reales de la CE sobre adquisiciones que involucran a empresas digitales, a saber: (i) Apple/Beats; (ii) Facebook/WhatsApp; (iii) Google/Doubleclick y; (iv) Microsoft/Skype. En este sentido, compararon los agentes económicos identificados como competidores por el algoritmo y evaluaron su similitud con respecto a los competidores detectados por la CE. Los resultados se muestran a continuación.
Tabla 1: Rivales encontrados por la CE y el modelo (“NLP”)
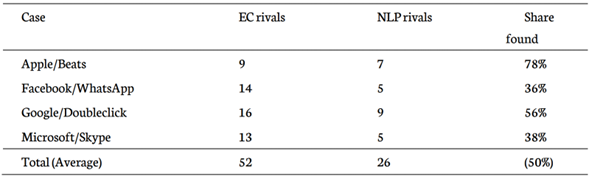
Fuente: Extraído de Gugler, Szucs y Wohak (2024)
Como es posible observar en la tabla, los resultados son mixtos: para los casos Apple/Beats y Google/Doubleclick, el algoritmo logró identificar una proporción no menor de los competidores identificados por la CE. Por otro lado, en los casos Facebook/WhatsApp y Microsoft/Skype, la tasa de coincidencia fue bastante menor. En este sentido, los autores establecen ciertos desafíos sobre el uso de esta herramienta, y uno de ellos es la ambigüedad de algunas descripciones (sobre todo cuando se trata de empresas muy grandes que están presentes en muchos mercados), lo que complejiza la operación del algoritmo.
No obstante, los autores destacan que existirían mejoras teóricas que se podrían implementar para optimizar el funcionamiento del algoritmo. Además, sugieren que el uso de estas técnicas computacionales deben complementarse con la “mano humana” (por ejemplo, se podría usar el algoritmo para un escaneo preliminar).