Newsletter
Suscríbete a nuestro Newsletter y entérate de las últimas novedades.
https://centrocompetencia.com/wp-content/themes/Ceco





CeCo tiene un amplio repositorio de jurisprudencia de libre competencia para Chile (666 casos), Ecuador (252 casos), Colombia (471 casos) y Argentina (414 casos), comprendiendo así un total de 1.803 fichas-resumen de casos. Este repositorio está asociado a un buscador por palabra(s) y filtros de categorías (p. ej., conducta y año), que es la manera tradicional de interactuar con bases de datos jurisprudenciales.
Dentro de los proyectos permanentes de CeCo, se encuentra el de explorar nuevas formas de interacción con el repositorio de jurisprudencia (p. ej., dashboards de fusiones para Chile y Perú). En este marco, los autores de esta columna (todos egresados del Diplomado en Legal Analytics de la UAI), desarrollamos un grafo de citas de sentencias de libre competencia, específicamente las dictadas por el TDLC en el periodo 2004-2025 (en adelante, “Grafo de Sentencias”). Esto se hizo construyendo una base de datos en formato JSON utilizando Python, y generando una visualización web con código HTML, CSS y JavaScript (entre otras herramientas).
«las citas se concentran más en las sentencias condenatorias que absolutorias. Así, mientras el 51% de las sentencias condenatorias realiza citas (43 de 83), solo un 37% de las sentencias absolutorias lo hace (44 de 114)».
Si deseas entender cómo se hizo del grafo y los hallazgos preliminares de esta herramienta, puedes seguir leyendo esta columna (y ver el grafo después). Si deseas ir directo al resultado, puedes ver el Grafo de Sentencias acá.
Para comenzar, es importante entender que un grafo es una forma de representar relaciones entre datos. En él, los datos toman la forma de nodos (o vértices) y las relaciones entre ellos toman la forma de líneas (o aristas). Así, el propósito del grafo es mostrar -visualmente- las conexiones (líneas) entre los nodos. Ejemplos de grafos, son el mapa del Metro de Santiago, los de citas de papers, y los de usuarios de una red social. La Figura 1 muestra distintos tipos de grafos, en los que la relación entre los datos adopta formas diferentes.

Figura 1: Tipos de grafos
¿Para qué sirve un grafo? Para observar cómo se estructuran las relaciones entre los datos y, eventualmente, detectar patrones que permitan acceder a un mayor conocimiento sobre ellos (a esto se denomina “network analysis”). Por ejemplo, veamos los grafos que se muestran en la Figura 1. El grafo de la izquierda revela que hay tres nodos que sobresalen respecto al resto (podría ser papers seminales sobre un área del conocimiento, o bien, sentencias que marcaron precedente). El grafo del medio exhibe distintos clústeres no conectados entre sí (lo que podría reflejar cierta especialidad o hermetismo en esos grupos de datos), y el grafo de la derecha muestra mayor dispersión (lo que revelaría que no hay conexiones de datos particularmente gravitantes).
En un grafo de citas de sentencias, los nodos son las sentencias y las líneas son las citas que una sentencia hace a otra. Se trata de un grafo de tipo “dirigido”, pues las líneas entre nodos tienen una dirección: desde la sentencia que cita hacia la sentencia citada. Por ello, en el Grafo de Sentencias las líneas (citas) se representan como flechas, que además varían en su tamaño, pues están ponderadas (“pesadas”) por la frecuencia de citas. Así, mientras más veces la “Sentencia A” cita a la “Sentencia B”, mayor grosor tendrá la flecha que conecta ambos nodos.
Cabe hacer presente que esta idea no se le ocurrió a CeCo. La agencia de competencia de Francia elaboró un grafo de citas existentes entre sus decisiones, opiniones y medidas cautelares, dictadas durante el periodo 2009-2021 (esto es, 1.043 documentos, que contienen 8.375 citas). El paper que explica este proyecto se puede ver acá y el código respectivo acá.
Se trabajó con 203 sentencias dictadas por el TDLC (procedimientos contenciosos infraccionales), es decir, desde la Sentencia N°1/2004 hasta la Sentencia N°203/2025. Con el fin de permitir un adecuado procesamiento del texto de las sentencias, estas se llevaron desde sus respectivos PDF a una base de datos en formato JSON (JavaScript Object Notation). Al igual que Excel (.xlsx), este formato permite estructurar datos a través de pares “clave-valor” (tal como lo hace una tabla común y corriente). En este caso, el “par” consiste en el número de sentencia (p. ej., N°174) y el texto de la misma. Ahora bien, a diferencia de Excel, JSON puede almacenar cuerpos de texto más extensos, permitiendo así procesar sentencias de más de 100 páginas sin perder la calidad del texto extraído.
Luego, para capturar las citas sobre esta base de sentencias en JSON de forma automatizada, se utilizó laherramienta “regex” (expresión regular) de Python. Esta permite definir secuencias abstractas de caracteres y buscarlas en un texto. De este modo, primero se observaron las distintas maneras (notaciones) en que el TDLC cita sentencias anteriores (p. ej., “Sentencia N° 133/2014”; “Sentencia 133/2014” o “Sentencia N°133-2014”). Luego se definió una expresión regular que internaliza todas las variaciones de las citas, de modo tal que es capaz de capturarlas a pesar de sus diferencias. Un ejemplo de regex (re) es el siguiente:
patron_sentencia = re.compile(r«sentencia[s]?\s+(n[ºo]|nos)?\s*[\d/ ,y]+», re.IGNORECASE)
Todo lo anterior dio lugar a una base de datos (JSON) compuesta de 151 sentencias (incluyendo tanto aquellas que citan como aquellas que son citadas; y omitiendo aquellas que no son citadas) y 927 citas. Ahora bien, si solo se contabilizan las citas únicas (es decir, si se excluyen las repeticiones de citas que hace una misma sentencia a otra), entonces el número de citas disminuye a 562. En otras palabras, el Grafo de Sentencias está conformado por 151 nodos (sentencias) y 562 líneas (citas).
Luego, esta base de citas se combinó con una base previa que categoriza las sentencias en 5 categorías: (i) conducta, (ii) mercado, (iii) resultado del fallo (condenatorio/absolutorio), (iv) número de sentencia y (v) año de dictación. Estas categorías son los “filtros” del Grafo de Sentencias.
Construcción del Grafo de Sentencias
Las primeras versiones del grafo se construyeron con la librería de Python ‘Networkx’, entre otras, y se trasladó a un entorno web utilizando la biblioteca vis-network.js, junto con una interfaz construida en HTML, CSS provista por Bootstrap (herramienta de código abierto para armar sitios web responsivos) y JavaScript que contiene las lógicas de la dinámica de la página. El grafo consume la base de datos final en formato JSON que tiene la siguiente forma:

Figura 2: Muestra de base de datos de citas en formato JSON
Respecto a la visualización de los datos, se tomaron las siguientes decisiones: (i) forma de los nodos: las sentencias de casos de colusión son triangulares, las de abuso circulares y las de incumplimiento de medidas cuadradas; (ii) colores de los nodos: cada color designa un sector económico (p. ej., telecomunicaciones es rojo y combustibles es calipso). Esto se muestra en la Figura 3:

Figura 3: Grafo de Sentencias
Además, se incluyó un panel informativo para cada nodo (sentencia), consistente en un recuadro que se despliega cada vez que se hace clic en el nodo. Este panel contiene información sobre el número de la sentencia, el año, la carátula, la conducta, el mercado y un hipervínculo hacia la ficha del caso en el Repositorio de Jurisprudencia de CeCo.

Figura 4: Ejemplo de panel informativo de nodo
Finalmente, en la parte inferior del grafo, se incorporaron controles de “física”, que permiten interactuar con el grafo aumentando o disminuyendo la gravedad y la distancia entre los nodos. Esto, con el fin de que el usuario ajuste la visualización del grafo según su preferencia.
En primer lugar, y como es natural, se observa una tendencia de aumento de número de citas a medida que transcurre el tiempo. Esto es esperable pues, a medida que pasa el tiempo, el acervo o “pool” de sentencias del TDLC que se pueden citar se va ampliando. Así, mientras a comienzos del año 2007 el TDLC solo tenía 46 sentencias previas a su disposición para citar, a comienzos del año 2024 tenía 190. Al respecto, ver Figura N°5 (nótese que la curva cae el año 2025 pues aún faltan meses para terminar el año).
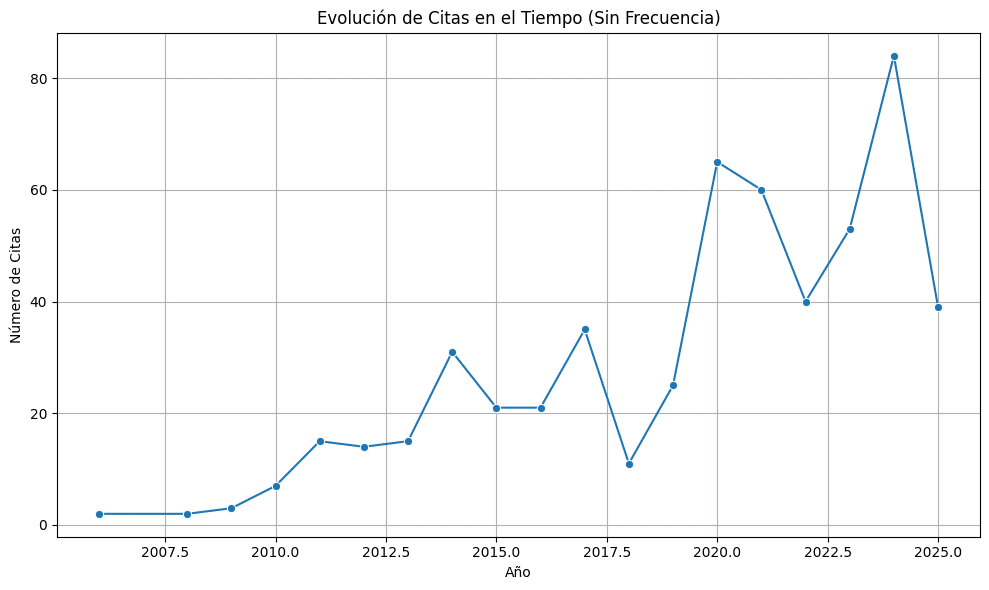
Figura N°5: Número de citas por año
En segundo lugar, de las 203 sentencias que ha dictado el TDLC hasta el momento de realizar este estudio (en procedimientos contenciosos), solo un 43% de ellas tiene una cita a otra sentencia del TDLC. Este 43%, equivalente a 88 sentencias. Es interesante notar que las citas se concentran más en las sentencias condenatorias que absolutorias. Así, mientras el 51% de las sentencias condenatorias realiza citas (43 de 83), solo un 37% de las sentencias absolutorias lo hace (44 de 114). Esto podría sugerir que el TDLC adopta un mayor celo en la búsqueda de precedentes al momento de condenar que al momento de absolver.
| Tipo de sentencia | Conteo | ¿Cuántas hacen citas? | % respecto del total de sentencias | % respecto del subconjunto (condenatorias/absolutorias) |
|---|---|---|---|---|
| Absolutorias | 114 | 44 | 21,7% | 38,6% |
| Condenatorias | 83 | 43 | 21,2% | 51,8% |
| Otros | 6 | 1 | 0,5% | 16% |
| Total | 203 | 88 | 43,4% | N/A |
En tercer lugar, se puede observar que los casos de colusión (nodos triangulares) forman un clúster (grupo) en un costado del grafo. Este clúster concentra más del 65% de los casos de colusión que contiene el grafo (27 de 42 casos). En cambio, los casos de abuso (nodos circulares) se posicionan con mayor dispersión en el grafo, sin formar un clúster claramente identificable. Esto se podría explicar por dos razones: (i) los casos de colusión tienden a citarse más entre sí que los casos de abuso, y (ii) los casos de abuso son mayor en número (son 127 nodos de abuso y 42 de colusiones), lo que dificulta que formen un clúster en el grafo.

Figura N°6: Clúster de casos de colusión
En cuarto lugar, si se observan los nodos considerando los mercados involucrados en cada caso (identificados en colores), se detecta que ciertos mercados parecen formar clústeres mientras que otros no. Por ejemplo, las sentencias del mercado de transporte (color naranjo) forman un clúster agrupando tanto casos de abuso como de colusión. Con todo, se advierte que, en algunos sectores económicos, las diferencias en las tonalidades de colores son tenues (a pesar de que se trata de un color diferente), dificultando este análisis.
En quinto lugar, al filtrarse las 10 sentencias más citadas (con el botón “Ver solo top 10 citadas”), se observan 6 nodos de colusión (sentencias 75, 133, 139, 141, 160 y 167) y 4 nodos de abuso (sentencias 57, 114, 131 y 176). Es interesante notar que, a pesar de que los casos de colusión apenas representan el 20% de todos los nodos del grafo (30 de 151), tienen el 60% de las sentencias Top 10 más citadas (6 de 10). Ahora bien, también se observa que los 6 casos de colusión más citados reciben citas tanto de casos de colusión como de abuso, y de distintos mercados. Esto podría sugerir que estas sentencias podrían ser citadas por factores distintos al tipo de conducta o tipo de mercado.

Figura N°7: Top 10 de sentencias más citadas
En fin, estos resultados son preliminares y deberán ser validados por estudios y procedimientos posteriores (p. ej., mejorar la metodología de extracción de texto captura de citas). En este marco, se invita a la comunidad CeCo a utilizar la herramienta y hacernos llegar sus comentarios al correo centrocompetencia@uai.cl.
*Agradecemos a los profesores Javier Wilenmann (UAI) y Rolando de la Cruz (UAI) por sus valiosos comentarios y críticas a lo largo de todo el desarrollo de este proyecto.
Regístrate de forma gratuita para seguir leyendo este contenido
Contenido exclusivo para los usuarios registrados de CeCo