Newsletter
Suscríbete a nuestro Newsletter y entérate de las últimas novedades.
https://centrocompetencia.com/wp-content/themes/Ceco

Hoy en día los algoritmos —de forma general— intervienen en diversos mercados, incidiendo en la decisión de consumo de los usuarios. Su uso en distintas industrias ha aumentado de la misma manera en que ha crecido la economía digital.
Solo para introducir el tema, Gómez-Uribe y Hunt (2015) mencionan que el 80% del contenido que es consumido en la plataforma de streaming “Netflix” proviene de recomendaciones que un algoritmo le realiza al usuario; y tan solo el 20% corresponde a una elección propia tras una búsqueda del consumidor.
Sin embargo, aunque existen un gran número de beneficios y posibilidades asociadas a la IA y el uso de distintos algoritmos (p. ej., la automatización de procesos), hay riesgos asociados al uso de estos que son importantes de analizar. En esta nota desglosamos el especial de junio 2023 de la revista Competition Policy International (CPI), titulado “Antitrust Chronicle – Algorithmic Bias” que trata sobre los sesgos de los algoritmos, los riesgos y sus beneficios, y qué pueden —o están— haciendo las autoridades de competencia para afrontarlos.
Giovanna Massarotto (Academic Fellow en el Center for Technology Innovation and Competition (CTIC) de la Universidad de Pensilvania), en su artículo “What is Algorithmic Bias and Why Antitrust Agencies Should Care?”, explica si acaso es posible que un algoritmo este sesgado.
Entendemos por sesgo una inclinación, o bien, una opinión preconcebida en donde se está predispuesto a decidir un asunto de cierta manera, sin estar abierto a una nueva convicción (The Law Dictionary, 1990). Por su lado, la definición general de algoritmo es la de un “manual de instrucciones” finitas que, en base a la entrega de un input, se da como resultado un output.
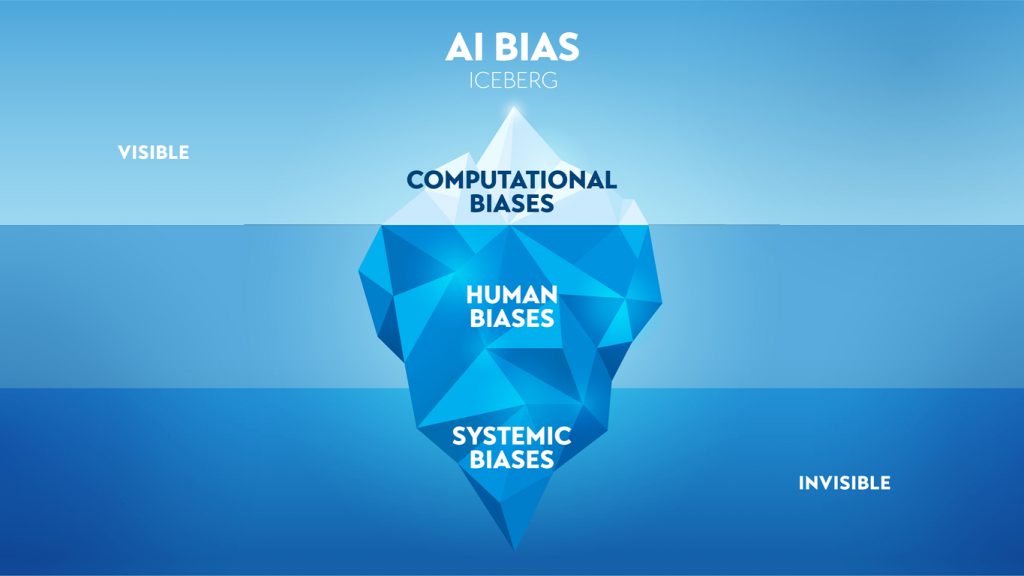
En este marco, el “sesgo algorítmico” se refiere a situaciones en las que este genera resultados (outputs) que son injustos para ciertos grupos de personas.
Dado el funcionamiento de los algoritmos, estos requieren que exista un conjunto de datos que el algoritmo procese para entregar un output, y una codificación del algoritmo (esta sería la “tinta” del manual de instrucciones). Entonces, tal como indica Massarotto, el potencial sesgo de un algoritmo o una IA puede ser causa de: (i) problemas en la representatividad de los datos que son entregados como input para el algoritmo; y/o (ii) sesgos humanos del desarrollador del software al momento de diseñar, codificar o entrenar al algoritmo.
En palabras simples, los algoritmos -por sí mismos- no pueden inclinarse independientemente hacia ciertos resultados y no prefieren ciertas características a expensas de otras. Así, la fuente del sesgo algorítmico sería el propio prejuicio humano.
Aunque los primeros artículos que estudian la posibilidad de colusión por parte de los algoritmos de precios son más bien recientes, Robert Clarke (Queen’s University) y Daniel Ershov (University College London), en su artículo “Algorithmic Pricing and Competition”, hablan en profundidad sobre los problemas que pueden traer los algoritmos de fijación de precios para la competencia (ver nota CeCo “Especial ABA 2023: Un repaso a la colusión utilizando algoritmos de precios”).
Las jurisdicciones recién están recibiendo los primeros casos, y no parecen existir dudas en los riesgos de prácticas coordinadas (ya sea paralelismo consciente o colusión directa) que es posible asociar al uso de algoritmos, especialmente en los relacionados con fijación de precios (ver nota CeCo “Algoritmos y colusión: El nuevo caso de los Hoteles en Las Vegas”).
Sin embargo, un área menos estudiada es la posibilidad de prácticas exclusorias o explotativas por parte de las empresas que utilizan estos softwares. Las firmas con poder de mercado pueden utilizar algoritmos para perpetuar una posición dominante (p. ej., técnicas de venta atada o self-preferencing), afectando así la libre competencia.
El problema típico de self-preferencing ocurre cuando una empresa es dueña de la plataforma intermediaria y, además, compite aguas abajo con empresas que utilizan dicha plataforma para ofrecer sus propios productos.
Nuevamente, el ejemplo de Netflix es bueno para ilustrar lo anterior. Aunque Netflix es una plataforma de streaming que entrega contenido diverso —producido por varias empresas—, también produce contenido. Entonces, si al momento de realizar recomendaciones la plataforma tiene un sesgo hacia producciones realizadas por ellos mismos, puede surgir un problema de competencia.
Sin embargo, el problema más inmediato no sería la conducta misma de self-preferencing adoptada por Netflix u otras empresas, sino que más bien sería la poca capacidad de las autoridades para comprender la forma en que ésta funciona. Así lo exponen Emilie Feyler y Veronica Postal (NERA Economic Consulting) en su artículo “Can Self-Preferencing Algorithms Be Pro-Competitive?”. En él sugieren que se ignoran los beneficios pro-competitivos que puede tener el self-preferencing (p. ej., reducir los costos de transacción), y que podrían traducirse en una disminución de los precios finales en los consumidores.
Asimismo, señalan que la literatura económica no es concluyente sobre el efecto neto entre los beneficios pro-competitivos y las posibles consideraciones anticompetitivas de esta conducta (self-preferencing), concluyendo que la determinación del impacto final requiere de un análisis individual del caso (bajo la regla de la razón), observando el contexto competitivo y el mercado en cuestión.
Por último, Antonio Capobianco (subdirector de la División de Competencia de la OCDE) menciona que son pocas las industrias que ocuparían realmente algoritmos al momento de fijar precios o tomar decisiones comerciales (hasta el momento). Por lo mismo, al no ser una práctica generalizada, no debería llamar la atención de forma alarmante en las autoridades de competencia (al respecto, ver nota CeCo “El Impacto de los Algoritmos en la Competencia y el Derecho de Competencia (A. Capobianco)”).
Entendiendo que los algoritmos están sesgados, o pueden estarlo, —al igual que el actuar humano—, ¿cuál es la utilidad de ocuparlos? Holli Sargeant (PhD Candidate en la Facultad de Derecho de la Universidad de Cambridge) y Teodora Groza (PhD Candidate en la Sciences Po Law School), en su artículo “Unleashing the Power of Algorithms in Antitrust Enforcement: Navigating the Boundaries of Bias and Opportunity”, mencionan que los algoritmos pueden ser de gran interés para las autoridades si estos ayudan a detectar prácticas anticompetitivas. Agregan que, en gran medida, las preocupaciones que han surgido debido a los sesgos se debe a la poca comprensión técnica de éstos.
Han surgido críticas por la utilización de algoritmos en decisiones judiciales y gubernamentales —o como herramienta de apoyo para éstas— y el argumento principal se enfoca en que los sesgos tras el algoritmo perjudican a las personas (de forma directa).
Para ilustrar esto, y complementando lo expuesto por Massarotto, las autoras mencionan lo señalado por Hooker (2021), en cuanto a cómo un conjunto de datos puede perjudicar (sesgar) las decisiones (outputs) del algoritmo, en contra de un grupo determinado. En este artículo se utilizó un conjunto de datos de análisis facial que contenía una preponderancia de sujetos de piel más clara (es decir, la muestra estaba sesgada hacia sujetos con piel clara), lo que provocó que el nivel de confianza en dicho conjunto de datos indujera a tasas de error más altas para sujetos con piel más oscura. En cierto sentido esto suena lógico, el sesgo de nuestros datos provoca resultados sesgados, aunque el algoritmo de por sí no lo esté.
De un modo similar, las autoras muestran que los sesgos en estos algoritmos, y su aplicación en algunas áreas del derecho, puede ser particularmente perjudicial y sensible. El escándalo que provocó la asignación de subsidios por el cuidado de niños en Países Bajos, el 2021, es prueba de aquello y llegó a tal punto que ocasionó la dimisión del gobierno holandés.
En este caso, con la intención de crear perfiles de riesgo de las personas que solicitaban los subsidios, la Administración de Impuestos y Aduanas de los Países Bajos utilizó algoritmos en los que empleó “nombres que suenan extranjeros” y “doble nacionalidad” como indicadores de posible fraude. Como resultado, miles de familias (racializadas) de ingresos bajos o medios, fueron acusadas falsamente de fraude, requiriéndoseles que devolvieran los beneficios otorgados (que habían obtenido de forma legal). En conclusión, los algoritmos llevaron a la elaboración de perfiles raciales, provocando discriminación y afectando de forma importante a las personas (para más detalles puedes revisar el debate en el Parlamento Europeo).
Sin perjuicio de lo anterior, las autoras mencionan que el área del derecho de la competencia es particularmente útil para la utilización de algoritmos en las decisiones de sus autoridades ya que, a diferencia de áreas que tratan directamente con los derechos y responsabilidades de los sujetos humanos (p. ej., derecho penal o migratorio), el objeto regulatorio de las leyes antimonopolio son las firmas. Esto hace que los riesgos de sesgos o posibles discriminaciones operen a un nivel distinto: en lugar de estar discriminando a cierto grupo de la población, el algoritmo puede perjudicar a cierto tipo de empresas por su tamaño, origen, o industria.
Complementando lo anterior, las autoras mencionan que, en la medida que los mercados se vuelven más complejos, las investigaciones de las autoridades cada vez requieren más datos y tiempo para evaluar la situación. La utilización de algoritmos en el análisis de datos no solo puede hacer más eficiente el proceso, sino también reducir el sesgo humano.
De hecho, Sargeant y Groza van más allá y mencionan que la legislación actual, como la Digital Market Act (DMA) en la Unión Europea, que utiliza el tamaño de la empresa como indicador del potencial anticompetitivo (gatekeepers), ya está sesgada en contra de las grandes plataformas. En este sentido, confiar en herramientas algorítmicas puede inyectar algún matiz en el análisis de la autoridad, siendo este un movimiento en la dirección opuesta a la actual, reduciendo así el actual sesgo en lugar de amplificarlo.
Como tercer punto, las autoras mencionan que la legislación antimonopolio vigente es más bien flexible y deja un amplio espacio a la discrecionalidad y la evaluación del contexto de cada mercado (especialmente en la economía digital). Por lo mismo, se han levantado críticas mencionando un grado de incerteza jurídica que puede perjudicar a las firmas y sus decisiones comerciales. En consecuencia, algunas jurisdicciones han reaccionado buscando endurecer ciertos actos y prohibiendo de forma per se algunas prácticas.
Para las autoras, en contextos de mercados dinámicos, la confianza en instrumentos regulatorios detallados que contienen prohibiciones absolutas es inherentemente sesgada hacia el statu quo y privilegia ciertas estructuras de mercado a expensas de otras (al respecto, ver nota CeCo “La complejización de la libre competencia bajo mercados inciertos”).
Finalmente, como ejemplos concretos, los algoritmos y las IA —o técnicas de Maching Learning— puede ayudar a la autoridad en: (i) la selección y extracción de datos para detectar estructuras de mercado con mayor probabilidad de colusión, (ii) recopilar información de forma más rápida para identificar tendencias de precios y su evolución en el tiempo, o (iii) analizar datos de contratación pública con el fin de detectar prácticas de manipulación de licitaciones.
Pensar que el crecimiento de la economía digital no viene de la mano con la integración de distintos tipos de algoritmos es iluso. Para tener un correcto desarrollo y crecimiento de estos mercados es necesaria una comprensión plena del funcionamiento de estas nuevas tecnologías, lo que hasta el momento parece ser una tarea compleja.
A diferencia del análisis jurídico, en donde la decisión del juez va acompañada de explicaciones acerca de cómo se obtiene el resultado (i.e., condena o absolución), ciertas formas de IA no explican el proceso seguido para arribar a un output determinado. Sin embargo, usualmente esto no es porque sea imposible de explicar, sino más bien por la inmensidad de parámetros que utiliza la IA, y que no logran tener una correcta compresión humana.
De esta forma, un diseño cuidadoso del algoritmo puede entregarle confianza pública a este tipo de herramienta, pero además brinda la oportunidad de reducir los juicios humanos subjetivos a decisiones que deben ser basadas en datos imparciales, entregándole mayor transparencia a diversos procesos, especialmente cuando estos pueden depender de varias personas.