Newsletter
Suscríbete a nuestro Newsletter y entérate de las últimas novedades.
https://centrocompetencia.com/wp-content/themes/Ceco


Recientemente, la OCDE publicó una serie de background notes que buscan abrir (o continuar) el debate sobre diversos temas “de frontera” de libre competencia. En CeCo repasamos algunos de estos papers, específicamente los referidos a programas de delación compensada, competencia e innovación, teorías del daño en fusiones digitales, y economía circular.
En esta nota se revisa y explica el background note “Algorithmic Competition” (en adelante “Reporte OCDE”), elaborado por Antonio Capobianco y Daniel Westrik (ambos de la División de Competencia de la OCDE). Asimismo, se introducen algunos conceptos que, si bien no están desarrollados en el Reporte OCDE, vienen a ayudar a explicar algunos aspectos sustantivos de algoritmos e inteligencia artificial (IA).
Antes de introducirnos en el Reporte OCDE, cabe explicar -con peras y manzanas- qué es un algoritmo. En términos simples, un algoritmo es una secuencia finita de pasos que deben ser seguidos para cumplir una tarea. Esta secuencia permite transitar desde un estado inicial (input) a un estado final (output). En este sentido, una receta de cocina para hacer puré de papas es un algoritmo.
Usualmente, los algoritmos son representados a través de diagramas de flujo. Por ejemplo, a continuación se muestra el diagrama de un algoritmo que, al recibir como input un número natural “n” (p. ej., 5) retorna -como output- la suma de los números naturales que llegan hasta “n” (p. ej., 1+2+3+4+5 = 15).
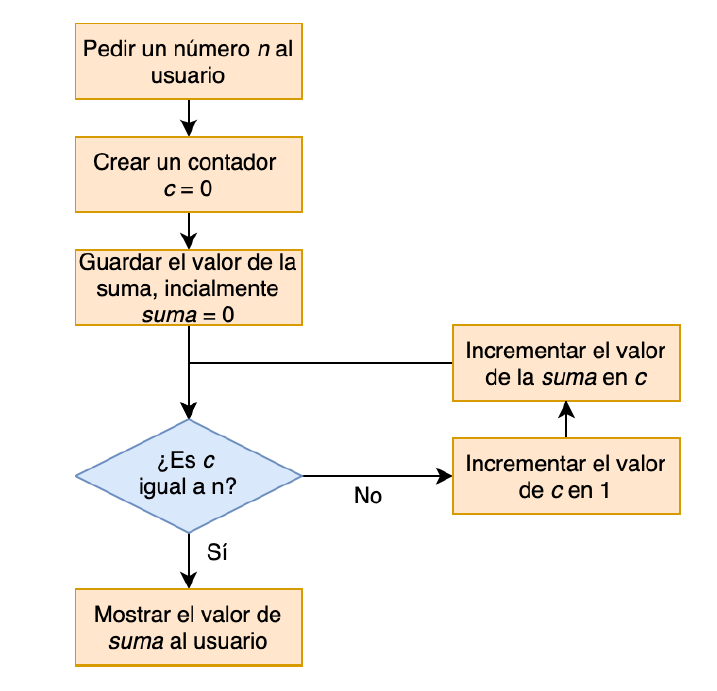
Fuente: Álvarez y Soto, Introducción a la programación en Python (2020)
Como se observa, el rombo azul del diagrama contiene un “loop”, el cual genera un ciclo iterativo. Estas iteraciones permiten ir contando cada número natural – partiendo por el 0 – hasta llegar al número “n”, y luego entregar como ouput la suma de esos números. Esta secuencia puede ser expresada en un lenguaje de programación (o “código fuente”), para dar lugar a un programa computacional (software). Para ilustrar, a continuación se muestra el algoritmo escrito en el lenguaje Python (nótese que el loop está en el comando “while”):
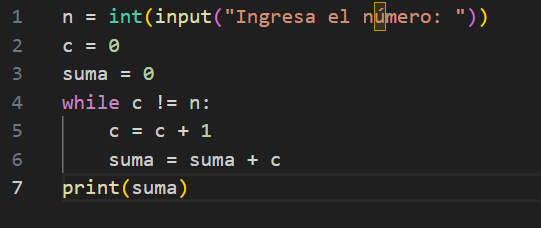
Fuente: Elaboración personal
Para que este algoritmo sea procesado y ejecutado por un computador (hardware), debe ser convertido a un “lenguaje de máquina” (también llamado “código objeto”). Este último es una representación binaria del programa computacional, consistente en patrones de 1s y 0s (bits), que a su vez son procesados por el computador como señales electrónicas que hacen operar sus circuitos y switchs.
Por supuesto, todo esto es una explicación simplista. Lo cierto es que hay muchos tipos de algoritmos (de baja y alta complejidad), los cuales a su vez operan con bases de datos (de mayor o menor tamaño), pudiendo servir para múltiples aplicaciones. En este sentido, de la mera lectura del código fuente de un algoritmo, rara vez se podrán sacar conclusiones relevantes para el derecho de la competencia. Esto pues dicha lectura no logrará capturar los resultados a los que puede arribar dicho algoritmo en base a su interacción con bases de datos, su entrenamiento y auto-aprendizaje.
Ya podemos cerrar el preludio y pasar a revisar el Reporte OCDE.
El Reporte OCDE se enfoca en los algoritmos que pueden generar mayores riesgos para la competencia.
En primer lugar, los algoritmos se pueden clasificar en atención a su función. Los más relevantes para el derecho de la competencia son los algoritmos de: (i) búsqueda (p. ej., Google Search), (ii) recomendación (p. ej., playlists automáticas de Spotify), (iii) alocación de demanda con oferta (p. ej., Uber), (iv) monitoreo de conductas (p. ej., Webwatcher), y (v) de fijación de precios (p. ej., Rainmaker Group).
Una segunda manera de clasificar algoritmos es según el tipo de tecnología que utilizan. En este sentido, el Reporte OCDE distingue entre algoritmos basados en IA, machine learning (ML) y deep learning (DL). Nótese que el DL es una subcategoría de ML, y este a su vez es una subcategoría de IA.
Los algoritmos de ML no solamente operan en base a las reglas codificadas que forman parte de su programación y base de conocimiento inicial (lo que es común en los algoritmos), sino que además pueden “aprender” de sus propias iteraciones y generar nuevas reglas.
Por su parte, el DL es un tipo de ML pero que se caracteriza por tener una arquitectura de IA especial, denominada “redes neuronales” (se llaman así porque replican la estructura del cerebro humano, operando en base a múltiples capas y nodos). Esta arquitectura permite procesar grandes volúmenes de datos y de distinta naturaleza (p.ej., texto, imágenes, audio), a través de procesos estocásticos o probabilísticos (es decir, distintos al razonamiento deductivo y determinista).
Desde el punto de vista del derecho de la competencia, los sistemas de DL pueden ser particularmente sensibles debido a su “opacidad”. Esta opacidad se produce porque su operación no se centra en reglas previamente programadas (es decir, código fuente que puede ser “leído” por un humano), sino que en los grandes volúmenes de datos (datasets) que son capaces de procesar (por esto se les denomina “data-driven”). Así, la forma en que los algoritmos de un sistema de DL arriban a sus resultados es difícil de trazar y explicar (constituyéndose como una “caja negra”). Esto a su vez puede generar problemas de interpretación e investigación para las autoridades de competencia.
Esta opacidad se vuelve aún más crítica con los denominados “Transformers”, que son una subcategoría de un sistema de DL. Estas son arquitecturas de IA que se fundan en redes neuronales pero que, además, incorporan un mecanismo llamado “auto-atención”, el cual le permite realizar ponderaciones más sofisticadas de los inputs y datos (Vaswani et al, 2017). Sin ir más lejos, las llamadas AI “generativas”, como Chat GPT, suelen ser “Transformers” (nótese que la sigla “GPT” significa “Generative Pre-Trained Transformer”).
Las teorías del daño asociadas al uso de algoritmos pueden ser tanto de conductas coordinadas (algorithmic collusion) como unilaterales (algorithmic exclusionary conduct).
El Reporte OCDE distingue tres escenarios. El primero es el de un algoritmo cuya función es facilitar la ejecución de un acuerdo colusorio previamente adoptado. Por ejemplo: tres competidores que acuerdan coludirse adoptan un algoritmo para fijar el precio de sus productos de forma automatizada, considerando una base de datos conformada por los precios de sus competidores en tiempo real. El algoritmo es capaz de detectar, de forma inmediata, cualquier desviación de precio y adoptar -automáticamente- los ajustes respectivos a la baja o al alza (lo cual “estabiliza” el cartel).
Al respecto, cabe advertir que, aún fuera de un escenario de acuerdo colusorio, la sola capacidad de los algoritmos de fijación de precios para detectar desviaciones y generar ajustes automáticos suaviza la intensidad competitiva. Esto, pues los competidores tienen menos incentivos a bajar sus precios si anticipan que dicha rebaja será inmediatamente “empatada” por el competidor que tiene el algoritmo, sin poder capturar nueva demanda.
El segundo escenario es un algoritmo que opera como un “hub” (en un esquema hub & spoke), permitiendo el intercambio de información estratégica entre competidores. Por ejemplo, tres competidores que no se ponen de acuerdo entre sí, contratan -por separado- un servicio de software de fijación de precios de un tercero, y le suministran información comercialmente sensible y no-pública a modo de input (p. ej., proyecciones de producción y/o precios). Luego, el algoritmo considera la información de los tres competidores y genera, como ouput, una estrategia de fijación de precios que resulta coincidente para las tres empresas, maximizando así las ganancias de todas. En este escenario, el algoritmo operaría como una instancia de intercambio de información estratégica entre las tres empresas.
Un caso de este tipo es el que comenzó en EE.UU. el año pasado, a través de una demanda contra de cuatro hoteles de Las Vegas Strip (ver nota CeCo: Algoritmos y Colusión: El caso de los hoteles en Las Vegas).
El tercer escenario que identifica el Reporte OCDE -acaso el más “ominoso” para el derecho de la competencia- es el de la colusión tácita algorítmica. Esta ocurriría cuando un algoritmo complejo (probablemente un sistema de DL), en base a su propio proceso de aprendizaje, genera como output una estrategia colusoria sin que exista un acuerdo previo entre competidores ni tampoco un intercambio de información (ver nota CeCo: “Remedios para colusiones tácitas algorítmicas”).
Cabe notar que el Reporte OCDE indica que, si bien han existido casos en que los algoritmos han sido utilizados para facilitar la ejecución de un acuerdo colusorio previamente adoptado, hasta la fecha del reporte no se habrían detectado casos en los que los mismos algoritmos, de forma autónoma, hayan generado una conducta colusoria.
Sin perjuicio de lo anterior, y ante la probabilidad de que los algoritmos de fijación de precios sean cada vez más utilizados por las empresas, el Reporte OCDE enfatiza la relevancia de identificar prácticas facilitadoras de colusiones tácitas algorítmicas. Algunas de estas prácticas -que podrían ser consideradas como plus factors– serían el intercambio de bases de datos (datasets) y comunicación de parámetros de decisión que podrían ser utilizados por los algoritmos.
Asimismo, el Reporte OCDE también destaca algunas propuestas para evitar o desestabilizar la colusión algorítmica y que seguirían una lógica de mercado (market-based). Así, por ejemplo, se menciona la conformación de “algoritmos de consumidores”. Estos consistirían en la unificación del poder de compra de un gran grupo de consumidores a través de un algoritmo capaz de alocar su demanda de forma automática ante una rebaja de precio (Michael Gal, 2022). Esto incentivaría a las empresas a bajar su precio, aunque sea por un instante (es decir, “justo antes” de que el algoritmo del competidor “empate” el precio rebajado), pues aquello le permitiría capturar la demanda de todo el grupo de consumidores.
El Reporte OCDE revisa tanto abusos exclusorios como explotativos. Dentro de los primeros, se refiere a conductas de self-preferencing, precios predatorios, descuentos, venta atada y empaquetamiento. Dentro de los segundos (explotativos), aborda los precios excesivos, condiciones comerciales inequitativas, y discriminación de precios.
Respecto a los abusos exclusorios, en el contexto de conductas de self-preferencing, los algoritmos pueden utilizarse para corregir situaciones de extracción imperfecta de rentas. Un ejemplo de esto es el ajuste que habría realizado Google a su algoritmo de búsqueda para favorecer la aparición de sus propios servicios de comparación de precios, relegando a los servicios de comparación de sus competidores (ver nota CeCo sobre caso Google Shopping en la Unión Europea). Dicha estrategia tenía por objeto mejorar la monetización de Google Search.
Otro caso de self-preferencing algorítmico es el de la app de taxis coreana “Kakao Mobility”. Esta app, de propiedad de Kakao, permite a los usuarios llamar tanto a taxis afiliados a Kakao (es decir, que pagan un fee de membresía) como a taxis independientes. Así, a través de un ajuste a su algoritmo de alocación de pedidos de taxi, Kakao favoreció a los taxistas afiliados (asignándoles de forma preferente las llamadas de los usuarios), relegando a los independientes. Esta conducta fue sancionada por la autoridad coreana de competencia (KFTC).
Por otra parte, los algoritmos también pueden ser utilizados para implementar precios personalizados en base a perfilamientos de usuarios (targeting), que permiten discriminar por capacidad/disponibilidad de pago. Para lograr esto, los algoritmos de fijación de precios pueden ocupar tanto filtros basados en contenido (considerando el historial de comportamiento del usuario), como filtros colaborativos (considerando el comportamiento de usuarios similares), operando con grandes bases de datos. De modo similar operan los algoritmos de recomendación, como los utilizados por Spotify para crear playlists automáticas (ver columna “Spotify, Discovery Mode, algoritmos”).
Adicionalmente, esta posibilidad de discriminar y segmentar mejor a los usuarios permite a las empresas optimizar las estrategias exclusorias. En efecto, si el algoritmo distingue correctamente a aquellos grupos de consumidores que pueden pagar más (denominados “infra-marginales”) de los que no pueden (denominados “marginales”), la empresa puede implementar una estrategia de precios predatorios, de venta atada o empaquetamiento que sea efectiva, es decir, sin correr el riesgo de perder a los consumidores marginales, a la vez que mantener la extracción de rentas a los infra-marginales. Para una explicación de esto, ver nota CeCo “Algoritmos en conductas exclusorias: ¿amenaza para la libre competencia?”.
Por último, esta posibilidad de discriminar entre consumidores también puede ser utilizada para implementar conductas explotativas, ya sea a través de precios excesivos, o bien, de condiciones comerciales inequitativas. Dentro de estas últimas cabría el empeoramiento que pueden producir los algoritmos de extracción de datos de usuarios, respecto a los niveles de protección de datos personales (al respecto, ver nota CeCo: “El tortuoso romance entre datos y competencia”).
En su capítulo final, el Reporte OCDE menciona algunas de las técnicas y maneras en que las autoridades de competencia pueden investigar los riesgos que pueden generar algunos algoritmos.
Un primer desafío que deben afrontar las autoridades es entender los algoritmos. Como ya se indicó, esto sería particularmente complejo respecto a los algoritmos de DL, que se sustentan más en su capacidad de auto-aprendizaje y manejo de grandes volúmenes de datos, que en su programación inicial, lo que los vuelve “opacos” frente al observador externo.
En otras palabras, salvo que el algoritmo esté “codificado” para cometer un ilícito anticompetitivo (p. ej., coludirse), de la sola lectura del código fuente del algoritmo puede que no se arribe a ninguna conclusión determinante.
Una forma de mejorar la “explicabilidad” de este tipo de algoritmos es a través del uso de métodos de ingeniería reversa. Otra alternativa (más intensa) sería que la regulación exija a los particulares la adopción de algoritmos interpretables (llamados “white box algorithms”). Adicionalmente, junto con revisar un algoritmo, puede resultar necesario examinar -y auditar- las bases de datos que utiliza dicho algoritmo. Estas bases de datos pueden incluir tanto aquellas que hayan sido utilizadas durante el “entrenamiento” del algoritmo para su proceso de aprendizaje, como aquellas utilizadas en su operación posterior.
Ahora bien, ha habido casos en que la revisión directa del algoritmo por parte de la autoridad (es decir, la lectura de su código fuente) ha generado buenos resultados. Por ejemplo, el Reporte OCDE destaca el caso “Trivago” (plataforma para encontrar alojamientos), revisado por la Australian Competition and Consumer Commission. El problema suscitado en este caso era que, en la mayoría de las búsquedas, la oferta de alojamiento más conveniente no era exhibida dentro de la “Top Position Offer” de la plataforma.
En este contexto, la autoridad australiana requirió el código fuente de los algoritmos de la plataforma de Trivago, con el fin de que sus científicos de datos (data scientists) lo revisaran “línea por línea”. Este examen le permitió a la autoridad, en una etapa posterior, ayudar al experto designado de común acuerdo con Trivago, a determinar las preguntas relevantes para su informe, así como también a analizar dicho informe.
Por último, el Reporte OCDE también propone algunas herramientas investigativas que las autoridades de competencia pueden adoptar para interpretar algoritmos. Al respecto, se menciona: (i) citar a declarar a los ingenieros informáticos que desarrollaron el algoritmo), (ii) requerir la exhibición del “pseudo-código” del algoritmo (documento que complementa el código fuente con explicaciones en lenguaje natural), y (iii) requerir los datasets que fueron utilizados para entrenar el algoritmo.